
Kurz erklärt: Wie funktionieren AI Agents?
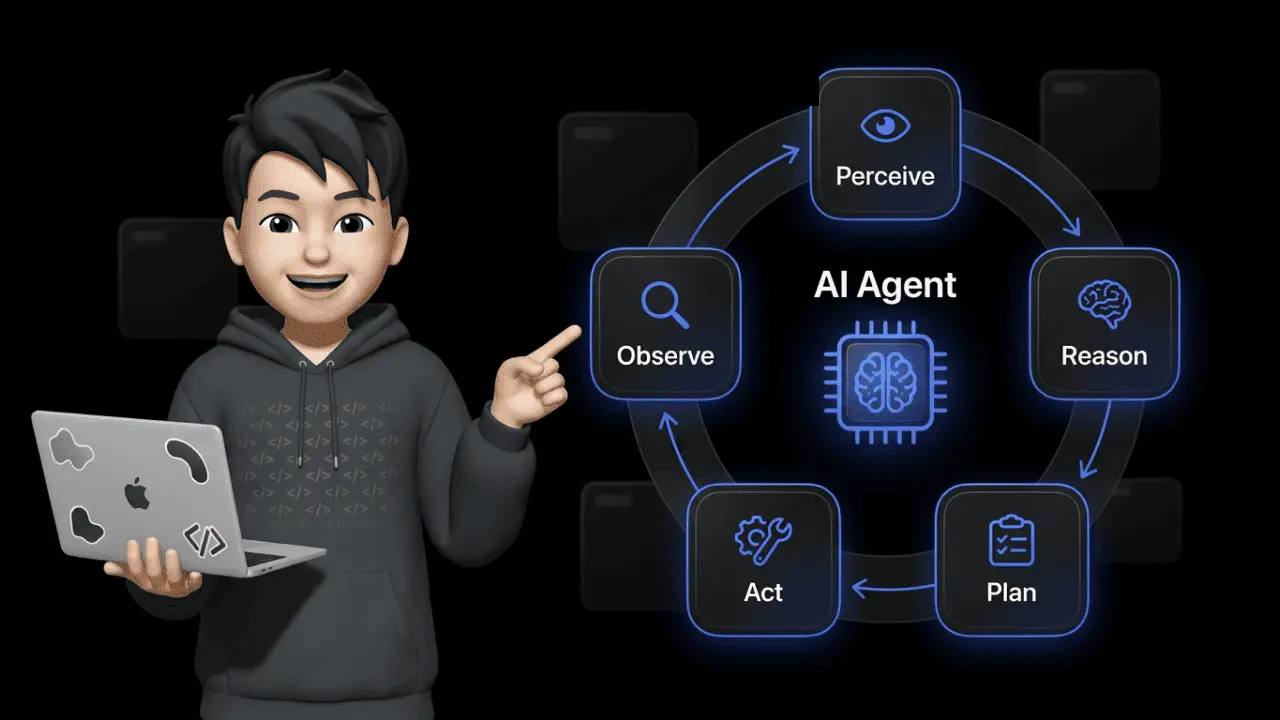
AI Agents arbeiten in einem kontinuierlichen Kreislauf aus Wahrnehmen, Denken, Planen, Handeln und Beobachten. Im Gegensatz zu Chatbots verfolgen sie autonom ein Ziel, nutzen externe Werkzeuge wie APIs und Datenbanken, korrigieren eigene Fehler durch Selbstreflexion und lernen aus jeder Interaktion.
Traditionelle KI vs. Agentische KI: Warum der Unterschied dein Geschäft betrifft
Die meisten „KI-Tools" auf dem Markt sind reaktiv. Du gibst einen Prompt ein, du bekommst eine Antwort. Kein Kontext, kein Gedächtnis, keine Eigeninitiative. Das ist generative KI — sie erstellt Texte oder Bilder auf Basis eines Prompts, aber sie handelt nicht.
Agentische KI dreht das Prinzip um. Statt auf Befehle zu warten, handelt ein AI Agent proaktiv und zielgerichtet: Er erkennt, was zu tun ist, plant die nötigen Schritte und führt sie aus — inklusive Fehlerkorrektur.
Gartner prognostiziert, dass bis 2028 rund 33 % aller Enterprise-Software agentische KI-Modelle integrieren werden. Gleichzeitig zeigt eine MIT-Analyse, dass aktuell nur 5 % der Enterprise-KI-Lösungen vom Pilot in die Produktion kommen — häufig weil Unternehmen reaktive Chatbot-Architekturen wählen, wo agentische Systeme nötig wären.
| Merkmal | Generative KI (Chatbot) | Agentische KI (AI Agent) |
|---|---|---|
| Verhalten | Reagiert auf Prompt | Verfolgt eigenständig ein Ziel |
| Planung | Keine | Zerlegt Aufgaben in Teilschritte |
| Gedächtnis | Nur aktueller Chat | Kurz- und Langzeitgedächtnis |
| Werkzeuge | Keine (nur Text) | APIs, Datenbanken, Websuche, UI |
| Fehlerkorrektur | Keine | Selbstreflexion und Anpassung |
Konkretes Beispiel: Ein Chatbot beantwortet „Wo ist meine Bestellung?" mit einem Standardtext. Ein AI Agent erkennt die Frage, greift auf das Shopsystem zu, prüft den Versandstatus und antwortet mit der tatsächlichen Trackingnummer — ohne menschliches Zutun.
Der Agent Loop: So arbeiten AI Agents Schritt für Schritt
Das Herzstück jedes AI Agents ist der Agent Loop — ein Kreislauf aus fünf Phasen, der sich wiederholt, bis das Ergebnis stimmt. Dieses Prinzip bildet die Basis des ReAct-Frameworks (Reasoning + Acting), bei dem der Agent nach jeder Aktion das Ergebnis beobachtet und seinen Plan dynamisch anpasst.
1. Wahrnehmen (Perception) Der Agent empfängt einen Input: eine Kundennachricht, ein Shop-Event, einen Datenpunkt. Er analysiert den Kontext und erkennt die Aufgabe.
2. Denken (Reasoning) Auf Basis seines LLM-Kerns bewertet der Agent die Situation, zieht Schlüsse und entscheidet, welche Strategie sinnvoll ist.
3. Planen (Planning) Der Agent zerlegt die Aufgabe in handhabbare Teilschritte (Task Decomposition). Erst Daten abrufen, dann prüfen, dann antworten.
4. Handeln (Action) Der Agent nutzt Werkzeuge — API-Calls an dein ERP, Datenbankabfragen, E-Mail-Versand. Er generiert nicht nur Text, sondern führt echte Aktionen aus.
5. Beobachten (Observation) Nach jeder Aktion prüft der Agent das Ergebnis. Hat der API-Call funktioniert? Falls nicht, springt er zurück zu Phase 2.
Diese Selbstkorrektur ist der entscheidende Punkt. Ein Chatbot gibt eine Antwort und ist fertig — egal ob richtig oder falsch. Ein AI Agent erkennt Fehler und korrigiert seinen Kurs.
Planung: Wie AI Agents komplexe Aufgaben zerlegen
Die Planungskomponente trennt einen AI Agent von einem besseren Autocomplete. Drei Techniken sind entscheidend:
Chain of Thought (CoT) — Schritt-für-Schritt-Denken Der Agent arbeitet ein Problem sequenziell ab. Jeder Gedanke baut auf dem vorherigen auf. Das reduziert Fehler bei komplexen Aufgaben drastisch.
Tree of Thoughts (ToT) — Mehrere Lösungswege parallel Bei Aufgaben mit mehreren möglichen Lösungen erkundet der Agent verschiedene Pfade gleichzeitig. Er bewertet jeden Zweig und wählt den vielversprechendsten — vergleichbar mit einem Schachspieler, der Züge im Voraus durchrechnet.
Selbstreflexion (Reflection) Andrew Ng, einer der profiliertesten KI-Forscher weltweit, bezeichnet Reflection als eines der wichtigsten Design-Muster für autonome Agenten. Der Agent bewertet seine eigenen Ergebnisse kritisch:
- War die letzte Aktion erfolgreich?
- Hat das Ergebnis die Aufgabe dem Ziel nähergebracht?
- Was muss beim nächsten Versuch anders laufen?
| Technik | Funktionsweise | Anwendungsfall |
|---|---|---|
| Chain of Thought | Sequenzielle Schritte | Standardanfragen, Troubleshooting |
| Tree of Thoughts | Parallele Lösungspfade | Komplexe Entscheidungen mit mehreren Optionen |
| Selbstreflexion | Bewertung eigener Ergebnisse | Fehlerkorrektur, Qualitätssicherung |
Gedächtnis: Warum AI Agents nicht bei Null anfangen
Ohne Gedächtnis ist jeder AI Agent ein aufgemöbelter Chatbot. Das Gedächtnis entscheidet, ob ein Agent Kontext versteht oder jedes Mal dieselben Rückfragen stellt.
Kurzzeitgedächtnis (In-Context Memory)
Das Kontextfenster des LLMs — alles, was der Agent innerhalb der aktuellen Session „sieht". Bei modernen Modellen sind das 100.000+ Tokens. Aber mehr Fenster heißt nicht mehr Intelligenz — dazu gleich mehr im Abschnitt Context Rot.
Langzeitgedächtnis (External Memory)
Das CoALA-Paper der Princeton University definiert drei Typen von Langzeitgedächtnis für AI Agents:
- Episodisches Gedächtnis: Erinnerungen an vergangene Interaktionen. „Dieser Kunde hat letzte Woche schon eine Retoure eingereicht."
- Semantisches Gedächtnis: Faktenwissen über Produkte und Richtlinien. „Rückgabefrist ist 30 Tage, außer bei Sale-Artikeln."
- Prozedurales Gedächtnis: Gelernte Abläufe. „Bei Reklamationen erst Bestellstatus prüfen, dann Fotos anfordern, dann Gutschrift auslösen."
Vektordatenbanken vs. Graph RAG
Vektordatenbanken (Pinecone, Weaviate) sind stark bei semantischer Ähnlichkeitssuche. Aber sie stoßen an Grenzen, wenn der Agent komplexe logische Beziehungen über mehrere Schritte verstehen muss. Graph RAG bildet Entitäten und Beziehungen explizit in Wissensgraphen ab. Für Multi-Hop-Abfragen — „Welcher Lieferant liefert das Ersatzteil für das Produkt, das Kunde X reklamiert hat?" — ist Graph RAG dem Vektoransatz überlegen.
Context Rot & Context Compaction: Warum mehr Tokens nicht mehr Intelligenz bedeuten
100.000 Tokens Kontextfenster klingt nach einem Freifahrtschein. In der Produktion ist es eine Falle.
Context Rot beschreibt den Leistungsabfall eines LLMs, wenn das Arbeitsgedächtnis mit irrelevanten Informationen überladen wird. Das Attention Budget des Modells ist endlich — je mehr Rauschen im Kontext, desto schlechter die Antwortqualität. Der NOLIMA-Benchmark belegt das messbar: Bei 32.000 Tokens Kontext fällt die Leistung von 11 getesteten Modellen auf unter 50 % ihrer Kurz-Kontext-Baseline.
Heißt konkret: Dein Agent hat alle Informationen im Fenster, aber er versteht sie nicht mehr. Er „ertrinkt" in seiner eigenen Historie.
Die Lösung: Context Compaction. Die Agent-Historie wird aktiv komprimiert — irrelevante Zwischenschritte entfernt, redundante Informationen zusammengefasst. Anthropics Leitfaden formuliert die Strategie so: „Maximiere zuerst den Recall (Vollständigkeit), um nichts zu verpassen, und iteriere dann auf Präzision, um unnötigen Ballast zu entfernen."
Das Agentic Context Engineering (ACE) Paper (2025) geht noch einen Schritt weiter: Ein System aus drei spezialisierten Agenten — Generator, Reflector und Curator — bereinigt den Kontext dynamisch. Ergebnis: 10,6 % bessere Benchmark-Leistung, ganz ohne Fine-Tuning. Drei Agenten, die nichts anderes tun, als den Kontext sauber zu halten.
Wer AI Agents in der Produktion betreibt, ohne Context Compaction zu implementieren, zahlt für Token, die die Antwortqualität aktiv verschlechtern.
Agentic RAG vs. Traditionelles RAG: Der Unterschied zählt
RAG (Retrieval-Augmented Generation) ist der Standard, um LLMs mit externem Wissen zu versorgen. Aber traditionelles RAG ist statisch: Suchen, Abrufen, Generieren — ein Durchlauf, fertig. Wenn die erste Suche schlechte Ergebnisse liefert, merkt das System das nicht.
Agentic RAG macht den Abrufprozess selbst agentisch. Der Agent:
- Formuliert eine Suchanfrage basierend auf der Nutzerfrage
- Bewertet die Qualität der gefundenen Dokumente
- Entscheidet: Reicht das? Oder muss die Suchanfrage umformuliert werden?
- Iteriert, bis die Informationsqualität stimmt
| Merkmal | Traditionelles RAG | Agentic RAG |
|---|---|---|
| Suchdurchläufe | 1 (statisch) | Mehrere (iterativ) |
| Qualitätsbewertung | Keine | Agent prüft Relevanz |
| Anpassung | Keine | Suchanfrage wird dynamisch optimiert |
| Ergebnisqualität | Abhängig vom ersten Treffer | Konvergiert zur besten Antwort |
Praxisbeispiel: Ein Kundenservice-Agent sucht die Retourenrichtlinie für ein bestimmtes Produkt. Traditionelles RAG liefert die allgemeine Richtlinie. Agentic RAG erkennt, dass die Antwort nicht produktspezifisch genug ist, formuliert die Suche um und findet die Ausnahmeregel für Sale-Artikel.
Werkzeugnutzung: API-Calls und Computer Use
Ein LLM kann nur Text generieren. Ohne Werkzeuge ist selbst das beste Sprachmodell ein besserer Texteditor. Tool Use macht den Unterschied zwischen „KI-Text" und „KI, die Aufgaben erledigt."
API-basiertes Tool Use (Function Calling)
Der klassische Weg: Der Agent erkennt, dass eine Aktion nötig ist, wählt das passende Werkzeug und formuliert einen strukturierten API-Call mit den richtigen Parametern.
| Werkzeug | Funktion | Beispiel |
|---|---|---|
| Shop-API (Shopify, JTL, Shopware) | Bestellungen, Retouren | Versandstatus abrufen |
| ERP-System (Xentral, Billbee) | Lagerbestand, Rechnungen | Gutschrift auslösen |
| CRM-Datenbank | Kundenhistorie | Kundenwert prüfen |
| E-Mail / WhatsApp API | Kommunikation | Versandbestätigung senden |
UI-basiertes Tool Use (Computer Use)
Nicht jedes System hat eine API. Zunehmend können AI Agents auch Benutzeroberflächen direkt bedienen — sogenanntes Computer Use. Der Agent erkennt Bildschirmelemente, simuliert Mausklicks und Tastatureingaben wie ein menschlicher Nutzer.
Das ist relevant für Legacy-Systeme im DACH-E-Commerce (Stichwort: Greyhound, PlentyMarkets), die keine modernen API-Schnittstellen bieten.
Aber Vorsicht: Die OWASP Top 10 für LLMs warnen explizit vor Excessive Agency — dem Risiko, dass Agenten zu weitreichende Handlungsbefugnisse ohne menschliche Kontrolle erhalten. Wer AI Agents produktiv einsetzt, braucht klare Berechtigungsgrenzen und Human-in-the-Loop-Freigaben für kritische Aktionen.
Infinite Loops & Kostenkontrolle: Wie du verhinderst, dass dein Agent Geld verbrennt
Stell dir vor: Dein Agent bleibt in einer Schleife hängen, ruft stundenlang dieselbe API auf und verbrennt nachts um 3 Uhr mehrere hundert Dollar Token-Kosten, bevor jemand es merkt. Kein hypothetisches Szenario — das passiert in der Produktion.
Einfache Iterations-Limits (Hard Limits) reichen nicht. Sie stoppen den Agent nach N Durchläufen, aber sie erkennen nicht, ob der Agent tatsächlich festsitzt oder nur eine komplexe Aufgabe sorgfältig bearbeitet. Bei teuren API-Calls (GPT-4-Klasse) kann der Schaden schon nach wenigen Minuten dreistellig sein.
Die Lösung: State-Level Circuit Breakers. So funktionieren sie:
- Nach jedem Schritt wird der Ausführungsstatus des Agenten per Hash-Wert erfasst
- Das System vergleicht den aktuellen Hash mit den vorherigen Zuständen
- Wiederholt sich ein identischer Status innerhalb von 30 Sekunden, greift der Circuit Breaker und stoppt den Agenten sofort
- Zusätzlich: Token-Budgets pro Task und Prompt-Caching, um redundante LLM-Calls zu vermeiden
| Schutzmechanismus | Funktion | Limitation |
|---|---|---|
| Hard Limit | Stoppt nach N Iterationen | Unterscheidet nicht zwischen Fortschritt und Loop |
| Token-Budget | Kostendeckel pro Task | Stoppt auch produktive Agents |
| Circuit Breaker | Erkennt identische Zustände | Braucht saubere State-Serialisierung |
| Human-in-the-Loop | Mensch genehmigt kritische Aktionen | Latenz, nicht 24/7 verfügbar |
In der Praxis kombinierst du alle vier. Ein einzelner Mechanismus reicht nicht.
Evaluierung & Observability: Agenten testen ist verdammt schwer
Einen AI Agent zu bauen ist eine Sache. Zu wissen, ob er funktioniert, ist eine ganz andere.
Das Problem: Ein Agent hat keinen deterministischen Output. Derselbe Input kann zu verschiedenen Toolchains, verschiedenen Zwischenschritten und verschiedenen Ergebnissen führen. Klassische Unit-Tests greifen hier nicht.
Zwei Ebenen der Evaluierung sind nötig:
Step-Level Tracing — Hat der Agent die richtigen Tools in der richtigen Reihenfolge aufgerufen? Wurde die API korrekt angesprochen? Wie viele Tokens hat jeder Schritt verbraucht? Hier geht es um den Weg, nicht das Ziel.
Outcome Scoring — Hat der Agent das Problem des Kunden tatsächlich gelöst? Das misst du entweder durch KI-Judges (ein zweites Modell bewertet die Antwortqualität) oder durch menschliche Bewertung. Hier geht es um das Ergebnis, nicht den Weg.
Tools wie LangSmith, Langfuse oder Maxim liefern die nötige Observability: Traces pro Agent-Run, Kostenaufschlüsselung pro Schritt, Latenz-Metriken und Qualitäts-Scores. Ohne diese Infrastruktur fliegst du blind — und blind fliegen mit einem System, das autonom API-Calls auslöst und Kundendaten verarbeitet, ist keine Option.
Für E-Commerce konkret: Wenn dein AI Agent eine Stornierung auslöst, willst du nachvollziehen können, welche Daten er geprüft hat, warum er die Entscheidung getroffen hat und ob das Ergebnis korrekt war. Tracing ist kein Nice-to-have, sondern Pflicht.
Die 5 Arten von AI Agents: Von simpel bis autonom
Nicht jeder AI Agent ist gleich gebaut. Die Einordnung bestimmt, was ein Agent leisten kann — und was nicht.
1. Einfache Reflexagenten Strikt regelbasiert: Wenn Bedingung X, dann Aktion Y. Kein Gedächtnis, keine Planung. Beispiel: Spam-Filter.
2. Modellbasierte Reflexagenten Wie Typ 1, aber mit internem Weltmodell. Sie berücksichtigen vergangene Zustände. Beispiel: Thermostat mit Trendanalyse.
3. Zielbasierte Agenten Haben ein definiertes Ziel und planen Aktionen voraus. Beispiel: Navigations-Agent mit Verkehrsdaten.
4. Nutzenbasierte Agenten (Utility-based) Vergleichen verschiedene Lösungswege und optimieren auf den höchsten Nutzen. Beispiel: Pricing-Agent, der Conversion und Marge balanciert.
5. Lernende Agenten Passen ihr Verhalten durch Feedback kontinuierlich an. Jede Interaktion verbessert sie. Beispiel: Kundenservice-Agent, der aus Eskalationen lernt.
| Typ | Gedächtnis | Planung | Lernfähigkeit | Praxisbeispiel |
|---|---|---|---|---|
| Einfacher Reflex | Nein | Nein | Nein | Spam-Filter |
| Modellbasierter Reflex | Ja (intern) | Nein | Nein | Thermostat |
| Zielbasiert | Ja | Ja | Nein | Navigation |
| Nutzenbasiert | Ja | Ja (optimiert) | Nein | Dynamisches Pricing |
| Lernend | Ja | Ja | Ja | KI-Kundenservice (z. B. armincx) |
Für E-Commerce sind lernende Agenten der relevante Standard. Alles darunter ist zu starr für Retouren-Management, Lead-Qualifizierung oder Support-Automatisierung.
Multi-Agenten-Systeme: Wenn ein Agent nicht reicht
Komplexe Geschäftsprozesse lassen sich selten mit einem einzigen Agenten abbilden. In Multi-Agenten-Systemen (MAS) arbeiten mehrere spezialisierte Agenten zusammen — jeder mit einer klar definierten Rolle.
Die sechs Orchestrierungs-Muster
Sequenziell (Pipeline): Agent A erledigt seinen Teil und übergibt an Agent B. Beispiel: Klassifizierung → Datenabruf → Antwortformulierung.
Parallel (Concurrent): Mehrere Agenten arbeiten gleichzeitig. Ein Synthesizer fasst die Ergebnisse zusammen.
Orchestrator-Worker: Ein Manager-Agent verteilt Aufgaben dynamisch an spezialisierte Sub-Agenten.
Group Chat / Debatte: Agenten diskutieren Lösungen und kritisieren sich gegenseitig. Eingesetzt bei Entscheidungen ohne eindeutige Lösung.
Blackboard: Agenten kommunizieren nicht direkt miteinander, sondern teilen Erkenntnisse asynchron über eine gemeinsame Wissensdatenbank. Jeder Agent liest, verarbeitet und schreibt zurück — ohne auf die anderen warten zu müssen. Ideal für Systeme, in denen Agenten unabhängig und in unterschiedlichem Tempo arbeiten.
Magentic-One: Ein Manager-Agent erstellt dynamisch ein Task-Ledger (Aufgabenliste), während spezialisierte Agenten die Aufgaben iterativ abarbeiten. Der Manager aktualisiert das Ledger nach jedem Schritt und verteilt neue Tasks basierend auf den bisherigen Ergebnissen.
| Muster | Kommunikation | Geschwindigkeit | Einsatz |
|---|---|---|---|
| Sequenziell | Linear | Mittel | Standardprozesse |
| Parallel | Via Synthesizer | Hoch | Recherche, Datenabgleich |
| Orchestrator-Worker | Hub-and-Spoke | Mittel | Enterprise-Workflows |
| Group Chat | Alle-zu-alle | Niedrig | Strategische Entscheidungen |
| Blackboard | Asynchron via DB | Hoch | Unabhängige Teilaufgaben |
| Magentic-One | Via Task-Ledger | Mittel | Dynamische, sich ändernde Aufgaben |
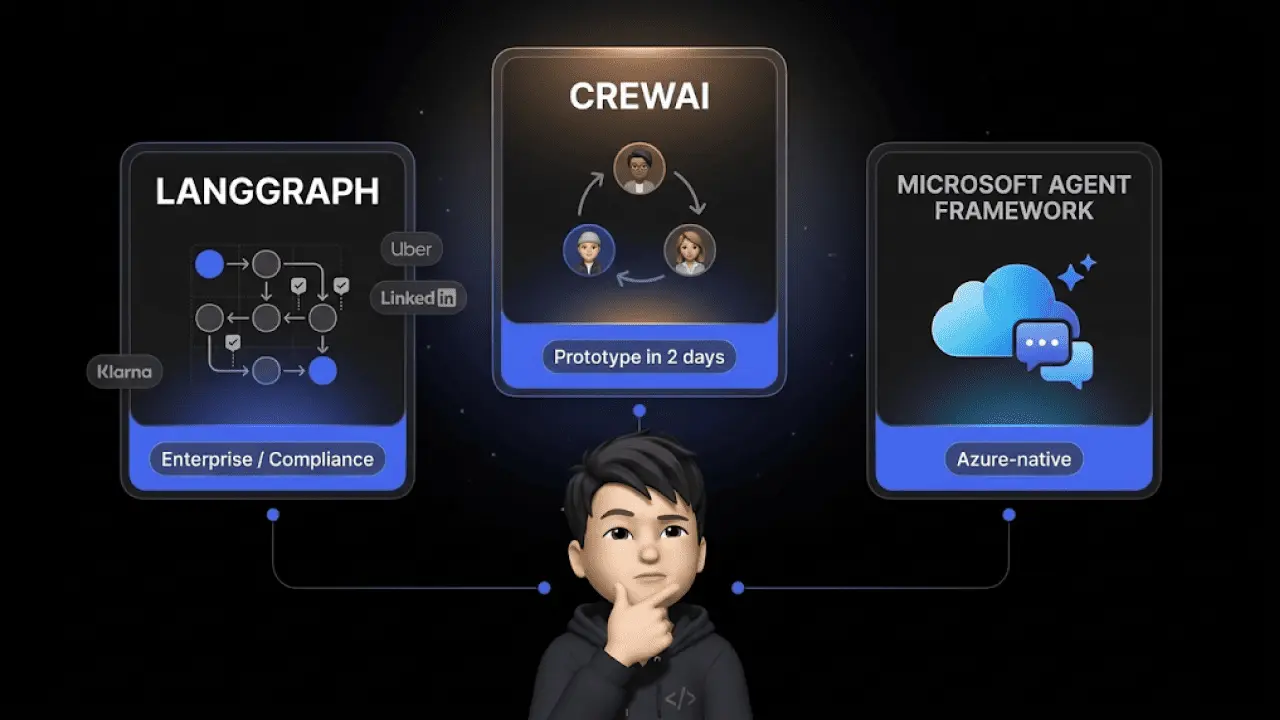
Die wichtigsten Frameworks für AI Agents im Vergleich
Wer AI Agents entwickeln oder evaluieren will, stößt auf drei dominante Frameworks. Jedes löst ein anderes Problem — und die Wahl hat Konsequenzen.
Eine Zahl, die das unterstreicht: Laut einer Cleanlab-Studie (2025) bauen 70 % der regulierten Enterprise-Unternehmen ihren AI-Agent-Stack alle drei Monate komplett neu, weil die Technologie sich so schnell wandelt. Framework-Entscheidungen sind keine Einmal-Entscheidung, sondern ein laufender Prozess.
LangGraph (von LangChain) Baut Agenten als Zustandsgraphen — jeder Knoten ist ein Schritt, jede Kante eine Entscheidung. Maximale Kontrolle über den Ablauf. Trade-off: Steile Lernkurve.
CrewAI Fokus auf rollenbasierte Agenten-Teams. Du definierst Agenten mit klaren Rollen (Researcher, Writer, Reviewer) und lässt sie kollaborativ arbeiten. Trade-off: Weniger Kontrolle über den exakten Ablauf.
Microsoft AutoGen Setzt auf konversationsbasierte Zusammenarbeit: Agenten kommunizieren in natürlicher Sprache. Trade-off: Höherer Token-Verbrauch durch die Konversationen.
| Framework | Stärke | Ideal für | Trade-off |
|---|---|---|---|
| LangGraph | Kontrolle über Zustandsgraphen | Komplexe Workflows mit Bedingungen | Steile Lernkurve |
| CrewAI | Rollenbasierte Teams | Content-Pipelines, Arbeitsteilung | Weniger Ablaufkontrolle |
| AutoGen | Konversationsbasiert | Diskussion, iterative Problemlösung | Hoher Token-Verbrauch |
Für E-Commerce-Entscheider: Du musst diese Frameworks nicht selbst einsetzen. Aber du solltest wissen, worauf dein Anbieter aufbaut — und ob die Architektur zu deinen Use Cases passt. Plattformen wie Chatarmin bauen mit armincx auf einer eigenen Workflow-Engine, die Stornierungen, Adressänderungen und Retouren nicht nur plant, sondern tatsächlich ausführt.
Häufig gestellte Fragen (FAQ)
Was ist der Unterschied zwischen RAG und Agentic RAG?
Traditionelles RAG ruft Informationen nur einmalig ab, während Agentic RAG Suchergebnisse iterativ analysiert, bewertet und Suchanfragen bei Bedarf autonom anpasst.
Welche Frameworks gibt es für die Entwicklung von AI Agents?
Die bekanntesten Frameworks sind LangGraph für kontrollierbare Zustandsgraphen, CrewAI für rollenbasierte Agenten-Teams und AutoGen für konversationsbasierte Multi-Agenten-Systeme.
Was versteht man unter Tool Calling bei KI-Agenten?
Tool Calling (oder Function Calling) ist die Fähigkeit eines KI-Agenten, externe Werkzeuge wie APIs, Datenbanken oder Websuchen selbstständig aufzurufen, um reale Handlungen auszuführen.
Können AI Agents Benutzeroberflächen bedienen?
Ja, durch sogenanntes UI-basiertes Tooling (Computer Use) können Agenten wie ein Mensch Bildschirmelemente erkennen, Mausklicks simulieren und Tastatureingaben vornehmen.
Wie speichern AI Agents langfristige Informationen?
AI Agents nutzen Vektordatenbanken für semantische Ähnlichkeitssuchen und zunehmend Graph RAG (Wissensgraphen), um komplexe logische Beziehungen über mehrere Sitzungen hinweg zu speichern.
Was ist ein Multi-Agenten-System (MAS)?
In einem Multi-Agenten-System arbeiten mehrere spezialisierte KI-Agenten kollaborativ zusammen, um komplexe Aufgaben zu lösen, die für einen einzelnen Agenten zu umfangreich wären.
Was bedeutet "Excessive Agency" bei künstlicher Intelligenz?
Laut den OWASP-Richtlinien beschreibt Excessive Agency das Sicherheitsrisiko, wenn ein KI-Agent zu weitreichende Handlungsbefugnisse hat und Aktionen ohne ausreichende menschliche Kontrolle ausführt.
Was ist der ReAct-Ansatz bei KI-Agenten?
Das ReAct-Framework kombiniert Reasoning (Denken) und Acting (Handeln), sodass der Agent nach jeder ausgeführten Aktion das Ergebnis beobachtet und seinen weiteren Plan dynamisch anpasst.
Was ist der Unterschied zwischen Generativer KI und Agentischer KI?
Generative KI erstellt auf Basis eines Prompts lediglich Texte oder Bilder, während Agentische KI proaktiv Ziele verfolgt, plant und Aufgaben in der realen Welt selbstständig ausführt.
Wie verhindern AI Agents Endlosschleifen?
Um Infinite Loops zu vermeiden, nutzen Entwickler Hard Limits für Iterationen, Token-Budgets sowie Human-in-the-Loop-Freigaben, bei denen kritische Aktionen von Menschen genehmigt werden müssen.
Was ist "Context Rot" bei AI Agents?
Context Rot beschreibt den massiven Leistungsabfall eines LLMs, wenn das Arbeitsgedächtnis mit zu vielen irrelevanten Informationen und langen Token-Ketten überladen wird.
Wie verhindern Unternehmen, dass AI Agents hohe API-Kosten verbrennen?
Um teure Endlosschleifen zu stoppen, nutzen Entwickler State-Level Circuit Breakers, die den Ausführungsstatus überwachen und bei Wiederholungen sofort abbrechen, sowie Prompt-Caching.
Was ist das Blackboard-Muster bei KI-Agenten?
Beim Blackboard-Muster kommunizieren Agenten nicht direkt miteinander, sondern teilen ihre Erkenntnisse und Zwischenergebnisse asynchron über eine zentralisierte, gemeinsame Wissensdatenbank.
Wie testet und evaluiert man AI Agents in der Produktion?
Die Evaluierung erfolgt zweistufig: Durch Step-Level Tracing (Überwachung der Werkzeugnutzung) sowie durch Outcome Scoring, bei dem KI-Judges oder Menschen prüfen, ob das finale Geschäftsziel erreicht wurde.
Was bedeutet Agentic Context Engineering (ACE)?
ACE ist eine Methode, bei der ein kollaboratives Agenten-Team (bestehend aus Generator, Reflector und Curator) den Kontext dynamisch bereinigt und optimiert, um Informationsverlust zu verhindern.
Fazit: AI Agents sind Infrastruktur — aber nur mit der richtigen Architektur
Die Technik hinter AI Agents ist klar: Agent Loop, Planung mit Reflection, Langzeitgedächtnis, Tool Use, Agentic RAG. Wer diese Komponenten versteht, kann Anbieter-Versprechen einordnen.
Aber die Technik allein reicht nicht. Die Produktion bringt Probleme, die kein Demo-Video zeigt: Context Rot, Infinite Loops, fehlende Observability, Excessive Agency. Laut MIT scheitern 95 % der KI-Projekte am Weg in die Produktion. Laut Cleanlab bauen 70 % der Enterprises ihren Agent-Stack quartalsweise komplett neu.
Wer AI Agents ernst nimmt, braucht Circuit Breakers, Context Compaction, Step-Level Tracing und klare Berechtigungsgrenzen. Alles andere ist ein teures Experiment.
Für E-Commerce-Unternehmen im DACH-Raum: Plattformen wie Chatarmin lösen genau diese Probleme mit armincx — ein AI Agent, der im Kundenservice 70–80 % der Tickets automatisiert, mit den richtigen Guardrails.
Du willst sehen, wie das in der Praxis aussieht? 👉 Jetzt kostenlose Demo buchen